Data is moved between systems via a data pipeline. To transfer data from source to target, data pipelines use a succession of data processing processes. Data may need to be copied, transferred from an on-premises system to the cloud, standardized, and joined with data from other sources, and other actions. In actuality, how we use constantly evolving data determines how successful a business is.
Businesses are burdened with the complexity and price of handling data independently as data-driven applications continue to expand. When you need to combine data from numerous sources to improve decision-making, the complexity increases. For planning and monitoring business models, analyzing organizational effectiveness, and other topics, you need data.
To efficiently acquire and handle vast amounts of data, a complete strategy is needed, one that makes use of well-designed data infrastructure and implements data-driven solutions. To be competitive, businesses must find the most strategic way to collect, transform, and extract value from data. Data pipelines can be used to do this. You will discover what streaming data pipelines are, how they operate, and how to construct this data pipeline architecture in this post. This blog will show you how to create a data pipeline and describe its operation.
How do pipelines for streaming data operate?
The information entering the pipeline is the initial phase in a streaming data pipeline. The software also decouples the creation of information from the applications that use it. This makes it possible to create low-latency data streams that can be altered as required. An analytics engine is then connected to the streaming data pipeline, enabling data analysis. Colleagues can also use the information to respond to business-related questions.
How important is a data pipeline?
Data pipelines are crucial for preparing data for analysis in conventional data architectures. The data proceeds through several processing processes before arriving at a data warehouse where it may be analyzed.
Businesses that rely on data warehouses for analytics and BI reporting must utilize a variety of data pipelines to get data from source systems through various processing phases and finally to end users for analysis. These companies can’t make the most of their data without data pipelines to transfer it to data warehouses. Because a no-copy lakehouse architecture decreases data migration, businesses that have embraced it can decrease the number of data pipelines they need to construct and operate.
Step-by-Step Process of a Data Pipeline
When constructing data pipelines, there are numerous elements to take into account, and early decisions can have a big impact on future success. The questions that should be put forth at the outset of the data pipeline design process are outlined in the following section. Designing a data pipeline involves several key steps to ensure that data is collected, processed, and analyzed effectively.
By following these steps, you can design an effective data pipeline that collects, processes, and analyzes data efficiently.
- Define the data source: Identify where your data is coming from and what data you need to collect. This may involve data from internal systems or external sources such as third-party providers.
- Determine data collection method: Determine how you will collect the data, whether it’s through APIs, scraping, or manual entry.
- Set up data storage: Determine how you will store the collected data. This could be in a database or a data warehouse. Ensure that the storage solution is scalable, secure, and can handle the volume of data you plan to collect.
- Data cleaning and preprocessing: Before analysis, it’s essential to clean and preprocess the data to ensure that it’s accurate and consistent. This may include removing duplicates, correcting errors, and transforming data into a standardized format.
- Data integration: If you’re collecting data from multiple sources, you’ll need to integrate it into a single dataset. This may involve merging, joining, or concatenating datasets.
- Data transformation: Depending on the analysis you plan to perform, you may need to transform the data further. This could involve aggregating data, filtering out irrelevant data, or creating new variables.
- Analysis and visualization: Once the data has been transformed, it’s time to analyze it. This may involve using statistical methods, machine learning algorithms, or other data analysis techniques. It’s also essential to visualize the data to communicate insights effectively.
- Deployment: Finally, it’s time to deploy the data pipeline. This may involve automating the pipeline, scheduling data collection, and setting up alerts and notifications to monitor the pipeline’s performance.
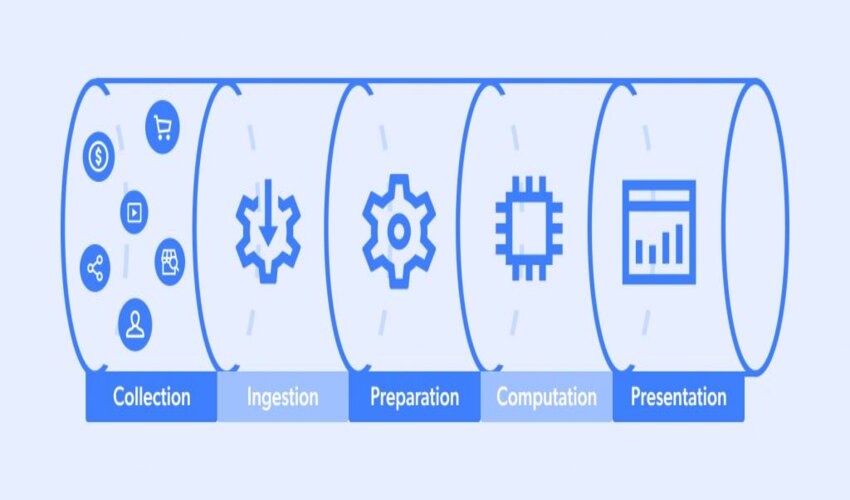
Architecture for data pipelines
The architecture of a data pipeline is composed of three fundamental steps.
1. Data ingestion:
Data is ingested from a variety of data sources, which may contain both structured and unstructured data in different forms. These raw data sources for streaming data are frequently referred to as producers, publishers, or senders. Businesses can decide to only extract data when they are prepared to analyze it, but it’s best to deposit the raw data in a cloud data warehouse provider first. In this manner, the company can update any past data if changes to data processing tasks are required.
2. Data transformation:
A number of processes are run at this phase to convert data into the format needed by the final data repository. For regular work streams like business reporting, these jobs integrate automation and governance to make sure that data is consistently cleaned and transformed. These altered data are frequently referred to as consumers, subscribers, or recipients in the context of streaming data.
3. Data storage:
After being changed, the data is stored in a data repository so that different stakeholders can access it. These altered data are frequently referred to as consumers, subscribers, or recipients in the context of streaming data.
Best Practices For Data Pipelines in Data Engineering
Here are some best practices for designing and implementing data pipelines in data engineering:
- Define a clear data strategy: Develop a clear strategy for data management and define the goals and objectives for data pipelines. This includes identifying data sources, defining data quality metrics, and setting up a data governance framework.
- Use a modular design: A modular design enables pipelines to be easily modified and extended as requirements change. It also enables the reuse of components across different pipelines, which saves development time and costs.
- Implement automated testing: Automated testing should be an integral part of the pipeline development process to ensure that the pipeline performs as expected and to catch any errors or bugs early in the development cycle.
- Implement data validation and quality control: Data validation and quality control mechanisms are critical to ensure that the data is accurate, consistent, and conforms to the organization’s data standards.
- Implement data security: Data security should be implemented at all stages of the pipeline development and execution process to protect data confidentiality, integrity, and availability.
- Use cloud-based services: Cloud-based services offer scalability, flexibility, and cost-effectiveness, making them an attractive option for building data pipelines.
- Use monitoring and logging: Monitoring and logging should be implemented to track system performance, detect issues, and provide insights into data usage patterns.
- Implement data version control: Data version control is critical for managing changes to the pipeline and data processing logic, enabling easy rollback in case of issues.
- Develop a disaster recovery plan: A disaster recovery plan is essential to ensure that the pipeline can be quickly restored in the event of a disaster or system failure.
By following these best practices, organizations can develop robust, efficient, and scalable data pipelines that meet their data management and processing needs.
Conclusion
Digital systems are supported by data pipelines. Pipelines help organizations to capture crucial insights by moving, transforming, and storing data. However, to keep up with the expanding complexity and number of datasets, data pipelines must be updated. While modernization requires time and effort, effective and contemporary data pipelines can help teams make choices more quickly and effectively, giving them a competitive advantage.
A data pipeline’s design, construction, and implementation are difficult, time-consuming, and expensive processes. Every component’s source code must be built by engineers, who must then flawlessly construct the connections between each component. Furthermore, a single modification may call for the reconstruction of the entire pipeline.
That is why the majority of businesses opt to purchase rather than construct. All of your data may be centralized, and a fully managed data pipeline system can deliver insights more quickly and affordably. To experience how simple it is to handle your data on our platform, try out W2S Solutions to provide data engineering services in a simple and efficient way right away.
Author Bio:
I am Vignesh Kumar, a passionate blogger who enjoys writing about technology. I work as a digital marketer with W2S Solutions, a provider of data engineering services with a high level of expertise.


